
TensorFlowのチュートリアルページ
TensorFlowの公式ページに様々なチュートリアルが掲載されています。本記事は、セグメンテーションのチュートリアルについて、実際にどう実行すれば良いのか、内容の解説も含めて書いていきたいと思います。
Google Colab
チュートリアルページでは、Google Colab(Google Colaboratory)という、ブラウザ上からPythonを実行できる環境を使います。もちろん、TensorFlowも使えますし、GPUも使えます。特に、ソフトをインストールする必要はなく、ブラウザで操作可能です。実際のプログラムの実行は、Googleのサーバーの方で行われます。
Google Colabは、Googleが無料で提供している仕組みです。ただし、Googleアカウントでログインをする必要があります。
セグメンテーションのチュートリアルページの紹介
以下がチュートリアルのページです。

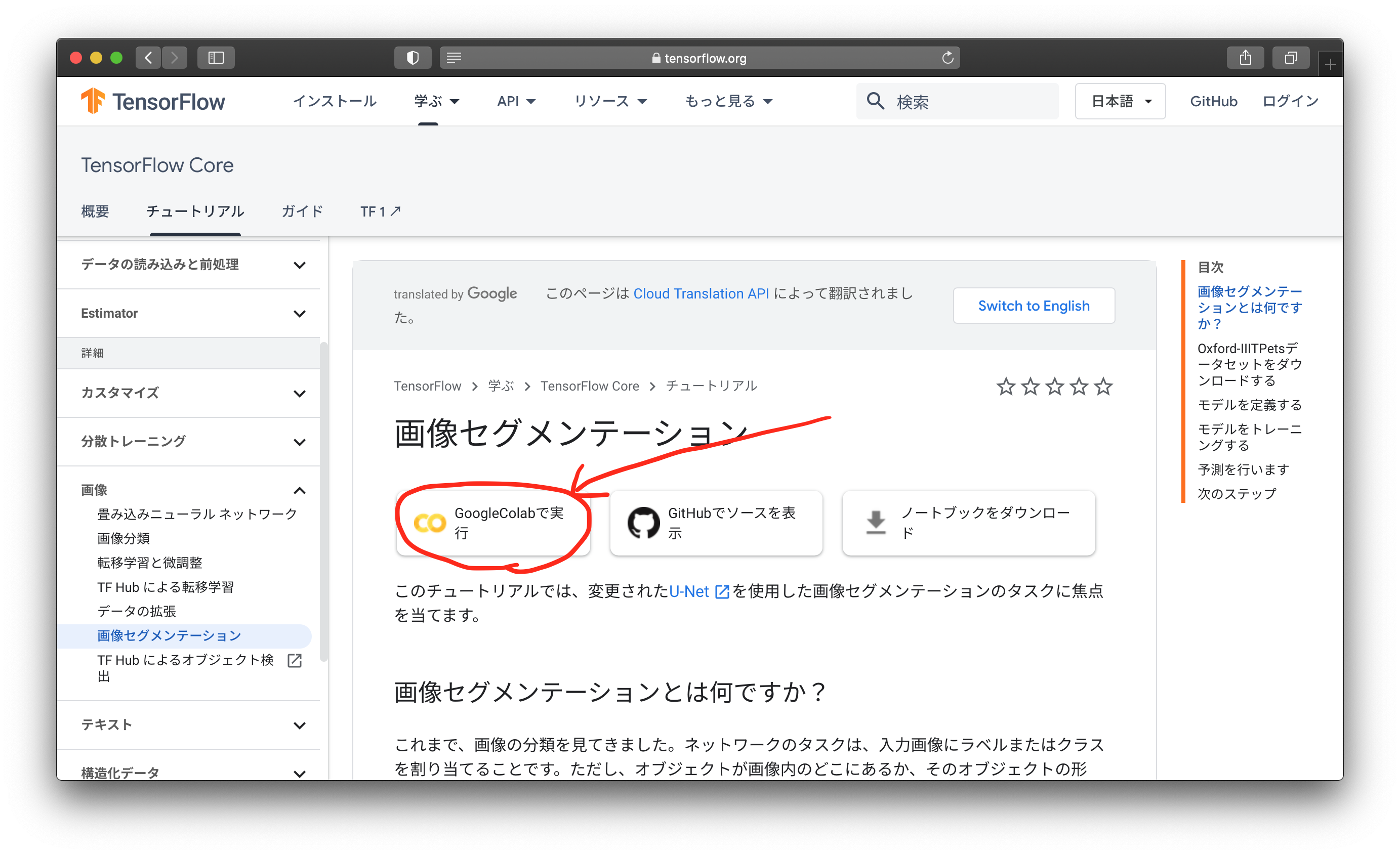
日本語で解説がされていますが、機械翻訳されたもののようで、意味がわからないところが多いです。赤丸で囲ったところからGoogle Colabのページに行けます。
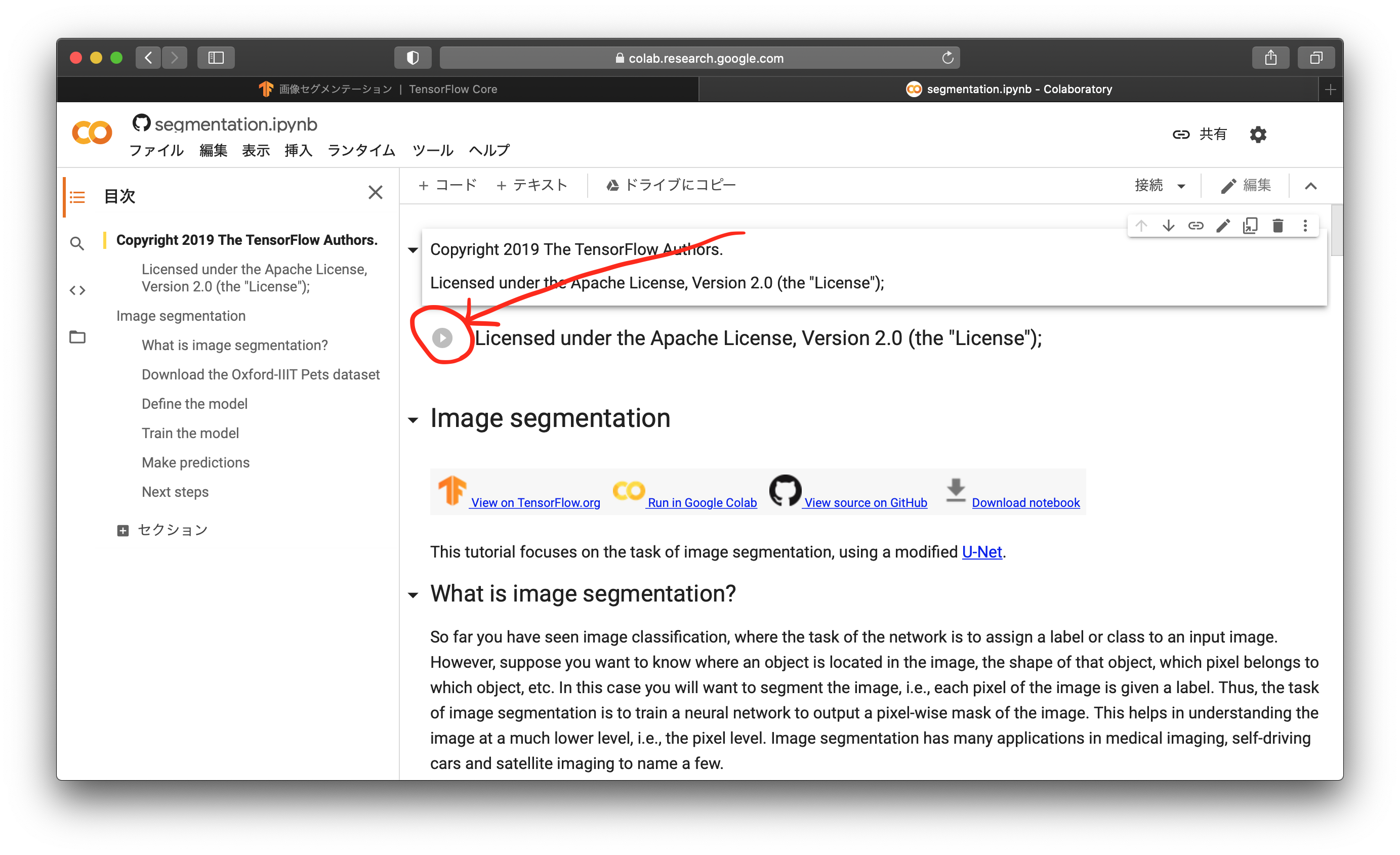
Google Colabのページは、全て英語で書かれています。通常のGoogle Colabは、ソースコードを自分で打ち込むのですが、このチュートリアルページは、コードが予め書かれていて、それを実行していく形になっています。まずは、書かれているソースコードのライセンスについて確認し、赤丸になているところをクリックします。しばらく経つと、Google Colabのインスタンスが用意され、準備が整います。
What is image segmentation?の部分に、このチュートリアルの概要が書かれています。セグメンテーションとは、画像内の物体の形状を導き出すものです。形状は、ピクセル単位のマスク画像として出力されるものです。このチュートリアルでは学習用データセットとして、Oxford-IIIT Pet Datasetというものを利用します。ペットの画像と、そのマスク画像がセットになったものです。マスク画像の各ピクセルは3つのクラスに分かれていて、1 : ペットの領域, 2 : ペットと背景の境界の領域, 3 : 背景の領域, になっています。
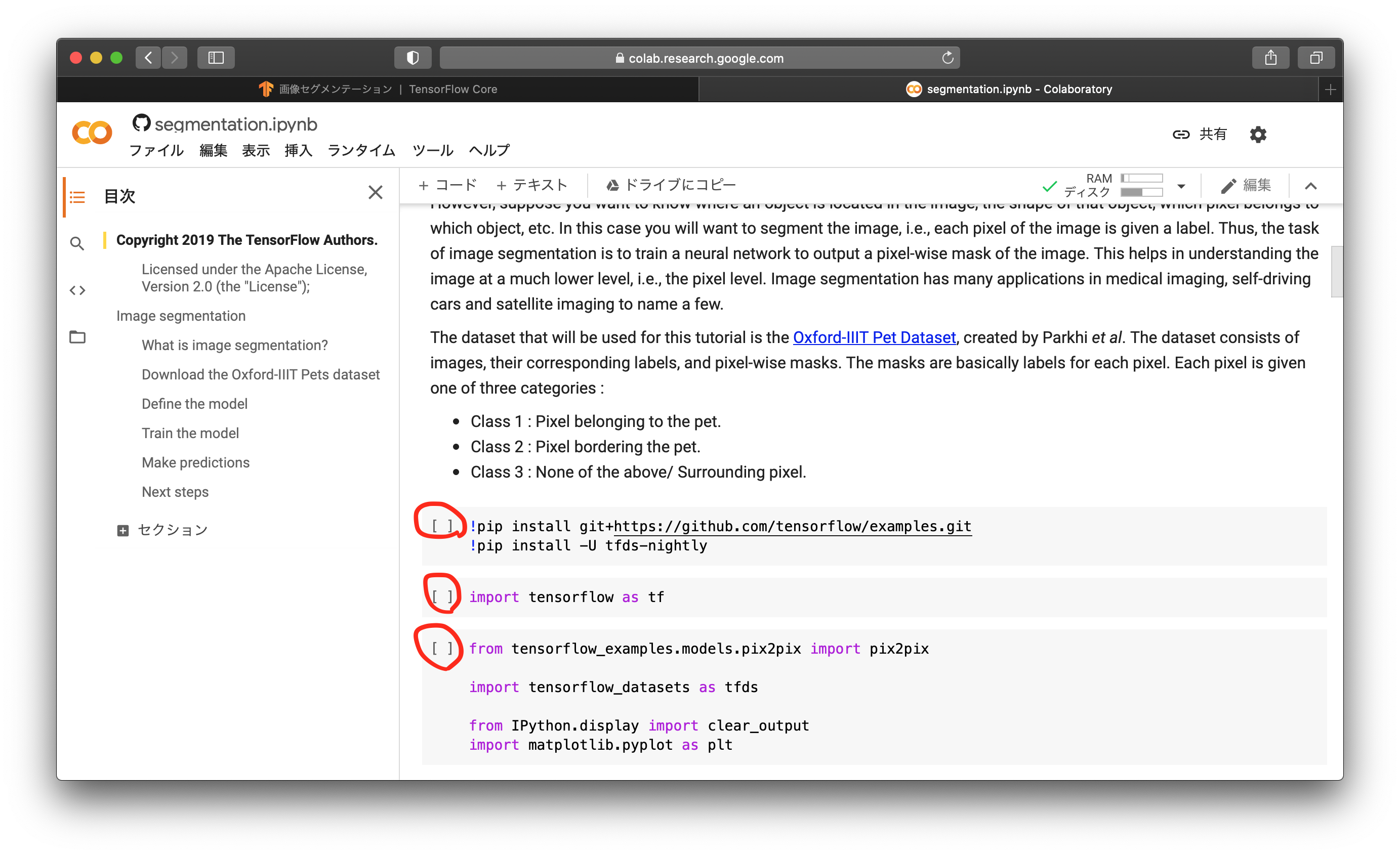
次にモジュール類をインストール/インポートします。3つの赤丸のところを上から順にクリックし、実行しましょう。ディープラーニングのフレームワークであるTensorFlowを使ったり、グラフ描画モジュールを使ったりすることを宣言しています。
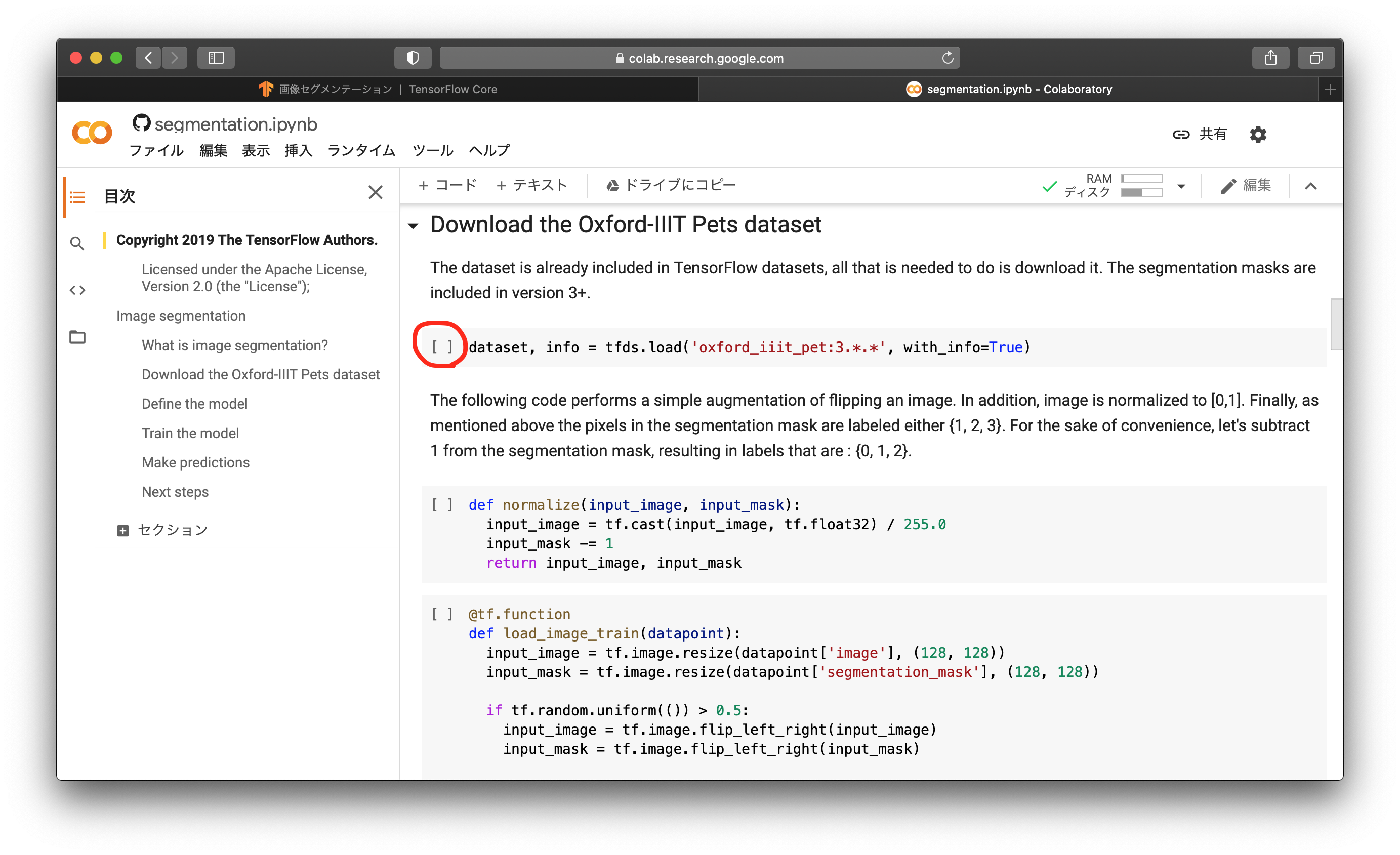
次に、データセットであるOxford-IIIT Pet Datasetをダウンロードします。赤丸のところをクリックしてください。
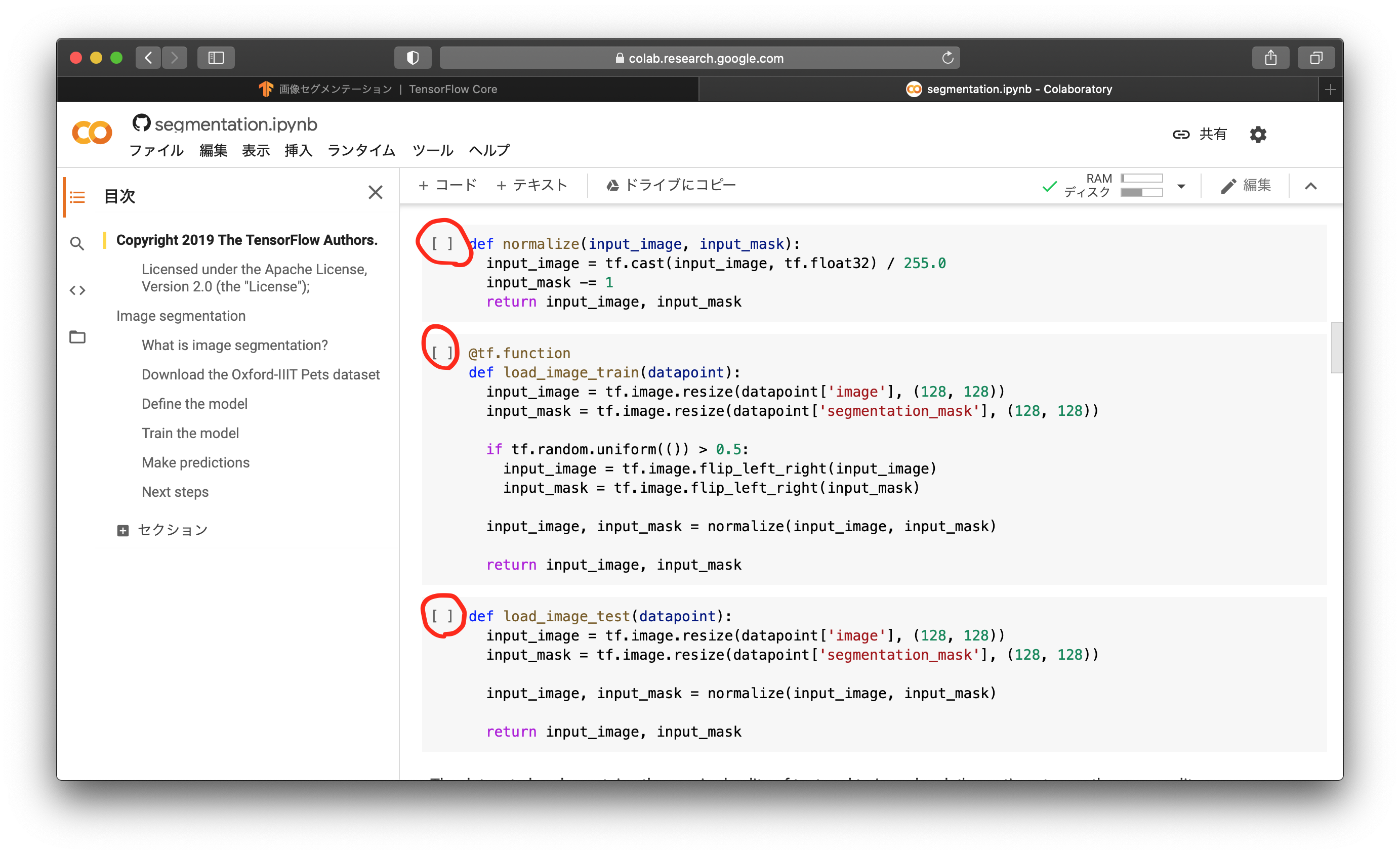
次に、ダウンロードしたデータセットを整形する関数を作ります。normalizeは、0〜255の値を持つ画像を0.0〜1.0の値に正規化します。ディープラーニングで画像を取り扱うときは、正規化か、標準化を行うのが一般的です。0〜255のまま学習をしてしまうと、学習が不安的になったり、発散したりすることがあります。load_image_trainでは、データセットを128x128pixelにリサイズし、50%の確率で左右フリップし、正規化して出力に渡します。フリップは学習用のデータ拡張です。load_image_testでは、データセットを128x128pixelにリサイズし、正規化して出力に渡します。テスト用画像なのでフリップはしません。上から順に赤丸のところをクリックしましょう。
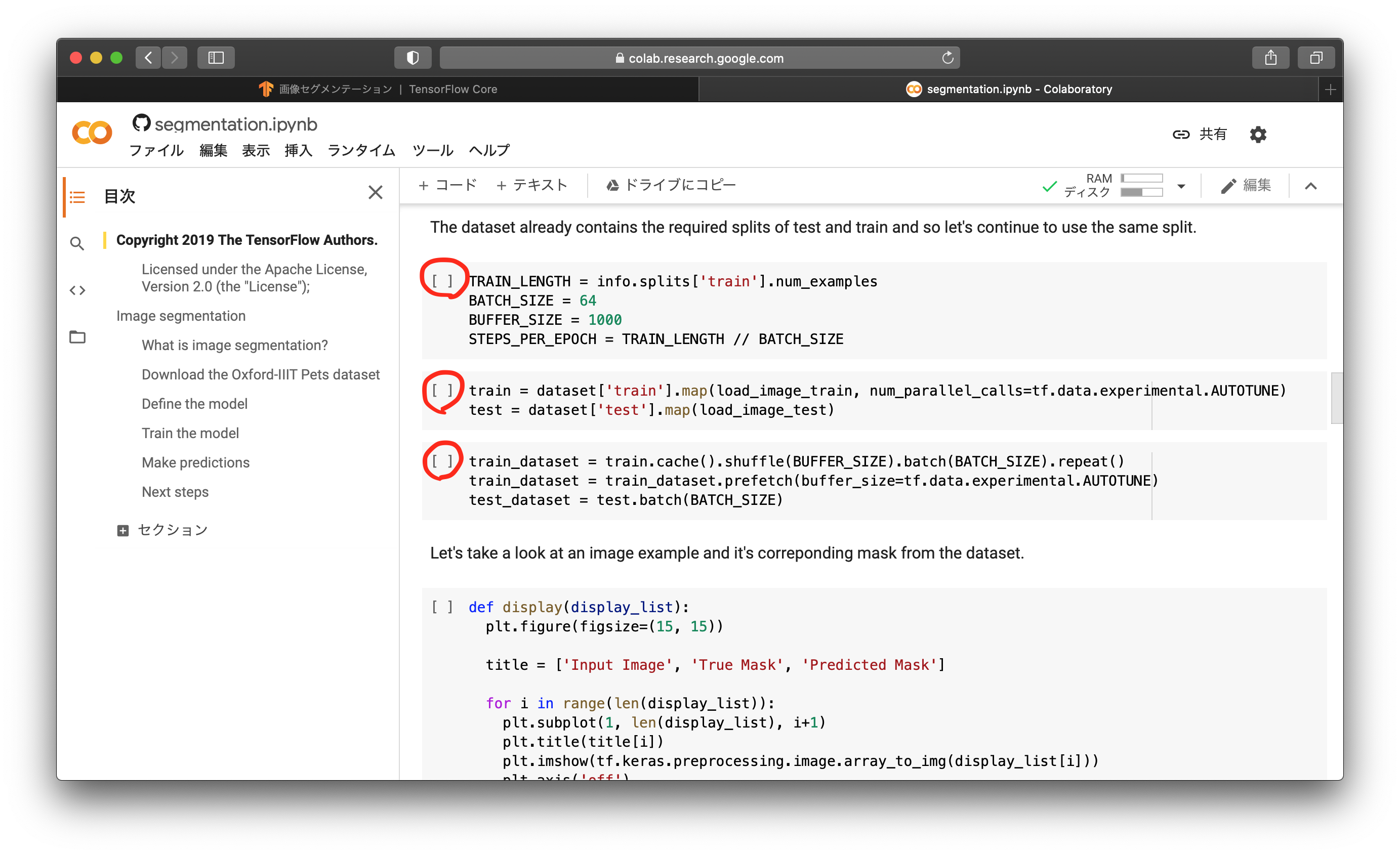
次に、ミニバッチサイズなどの値を設定し、学習用データセットとテスト用データセットを用意します。学習用データセットはシャッフルされるようにします。上から順に、赤丸のところをクリックしましょう。
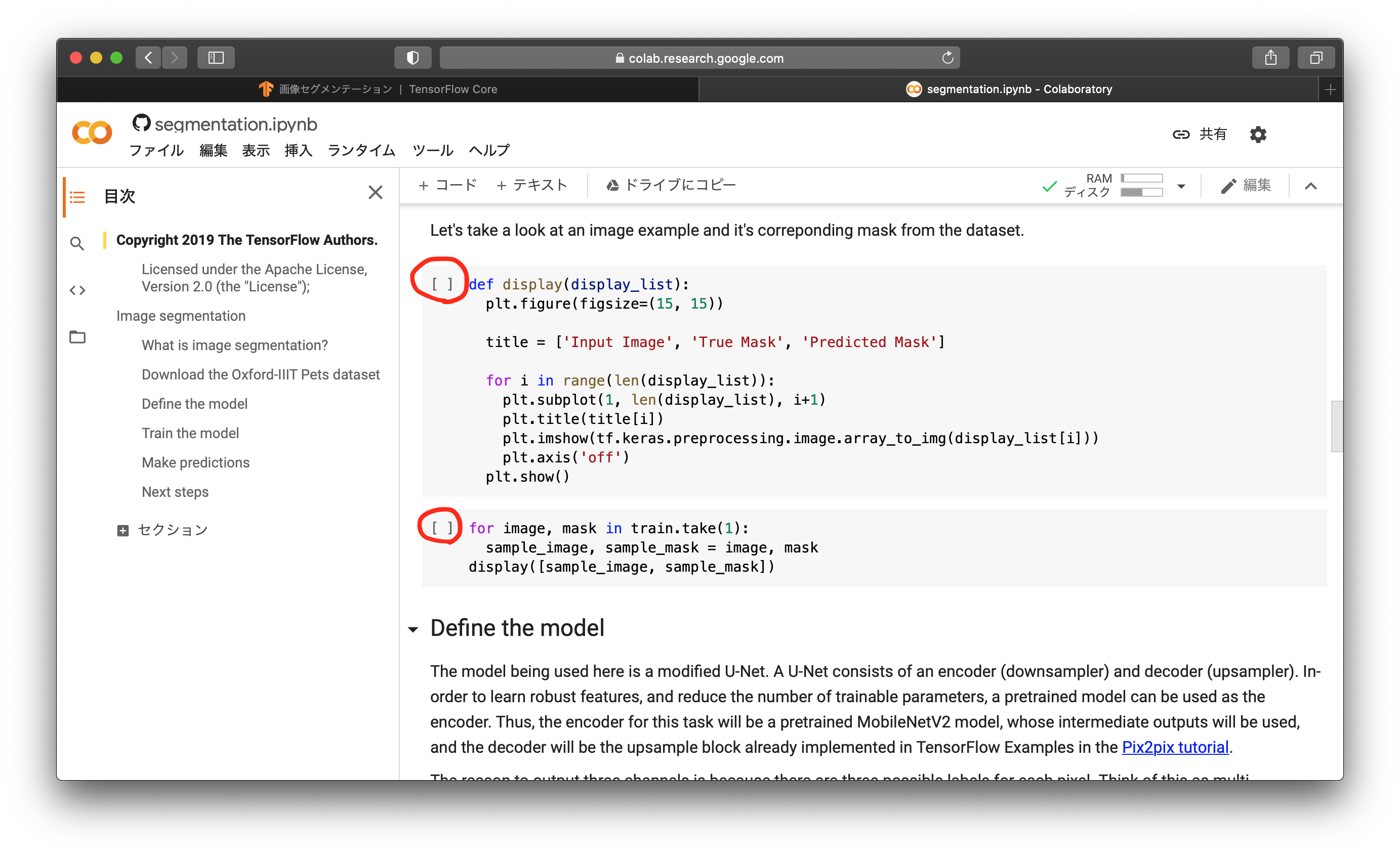
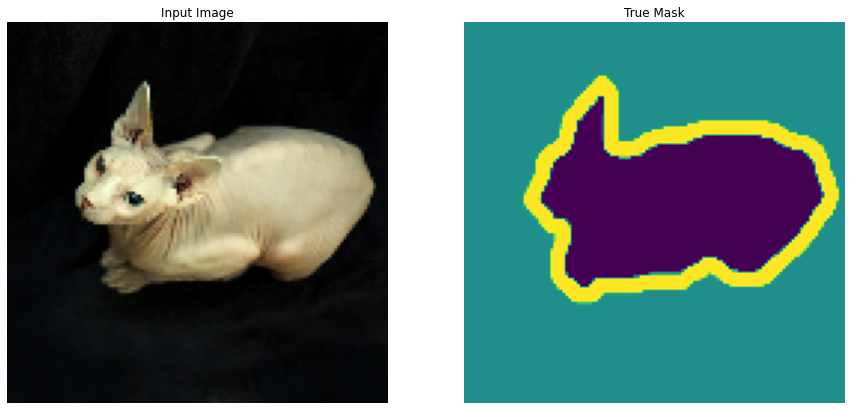
ここで、データセットにはどのようなペット画像とマスク画像が入っているのかを確認します。以下が実行結果です。猫の画像と、そのマスク画像が表示されることが確認できます。
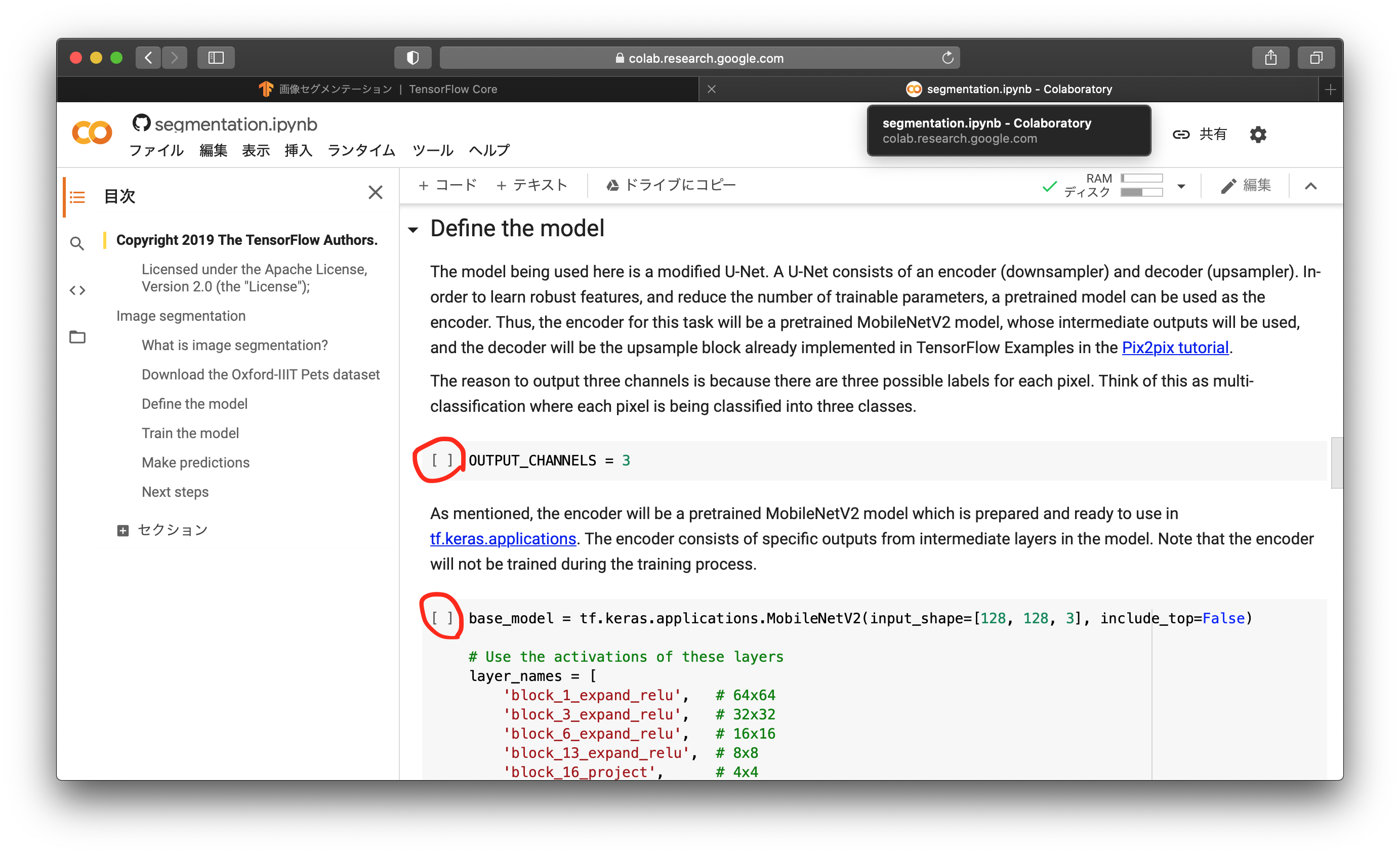
ここからは、ニューラルネットワークモデルを記述していきます。記述では、U-Netのモディファイ版を使うと書かれています。以下がU-Netの全体像です。
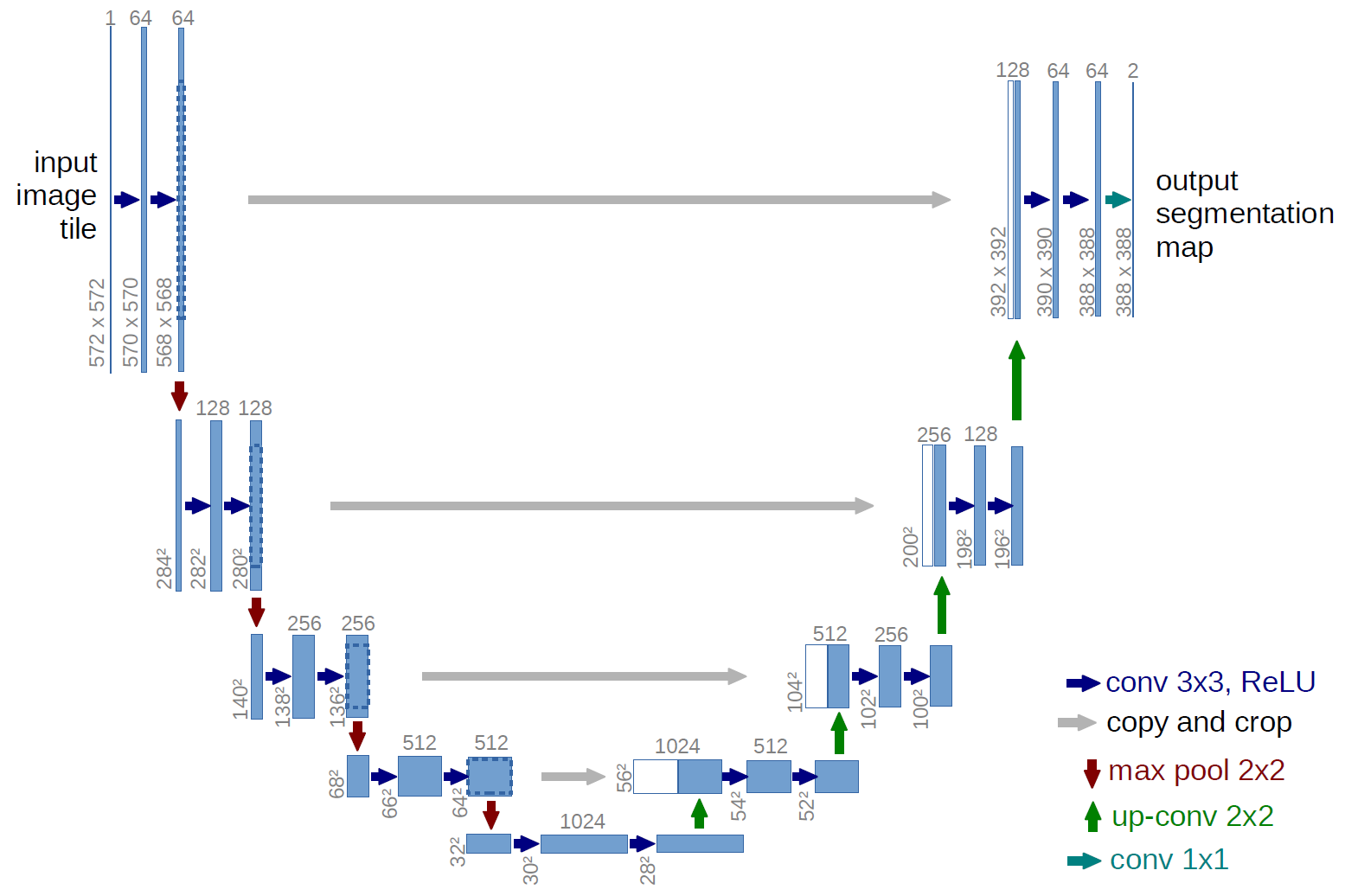
前半、画像をシュリンクさせ、後半はアップサンプリングして解像度を上げながら元の解像度で戻します。間をショートカットと呼ばれるルートが通っています。このチュートリアルでは、シュリンクさせる部分にMobileNetV2を流用し、アップサンプリングする部分はこのまま使います。まずは前半のMobileNetV2を読み込むところが書かれています。赤丸を上から順にクリックしましょう。
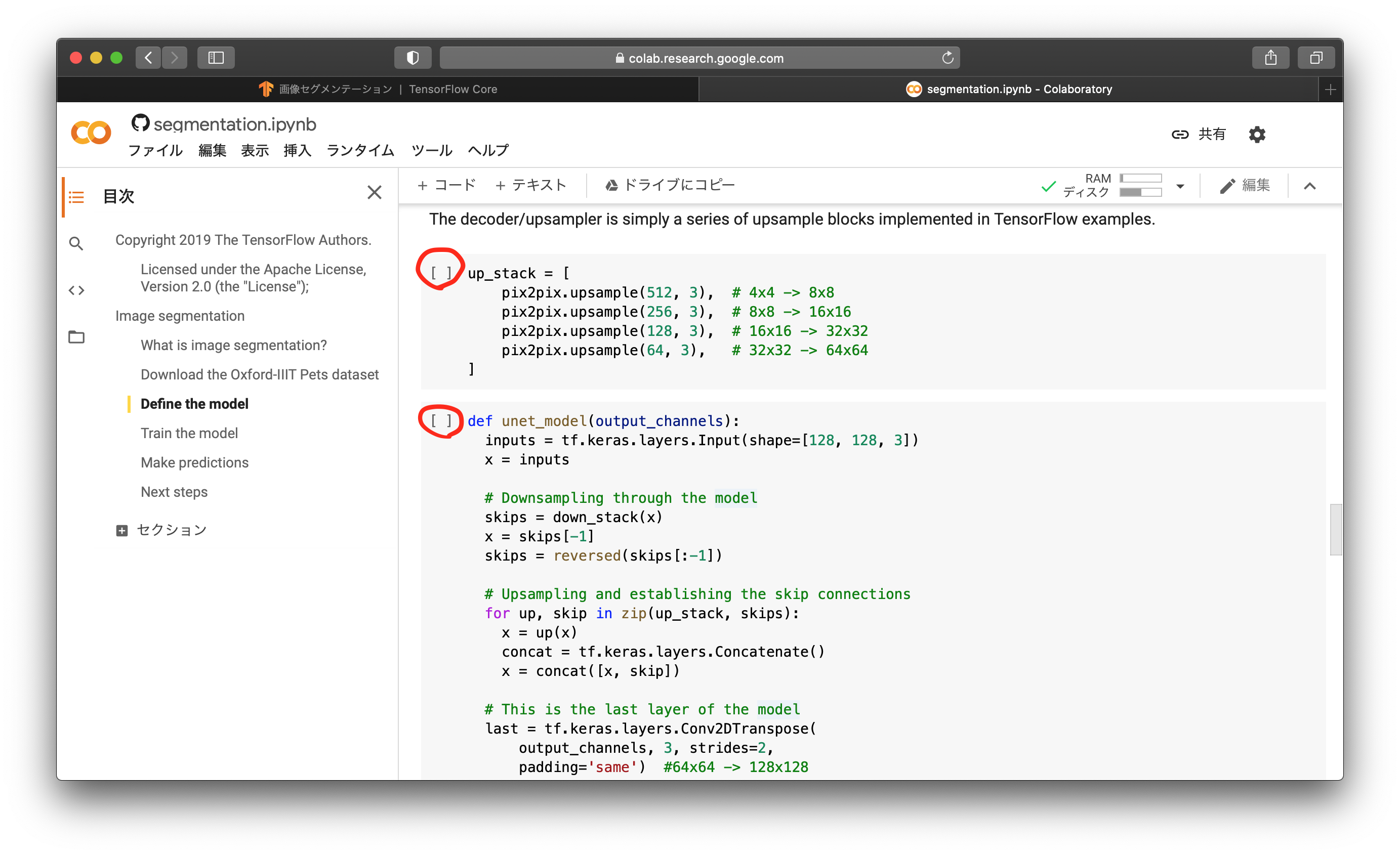
後半のアップサンプリング部分と、前半後半の結合について書かれています。赤丸を上から順にクリックしましょう。
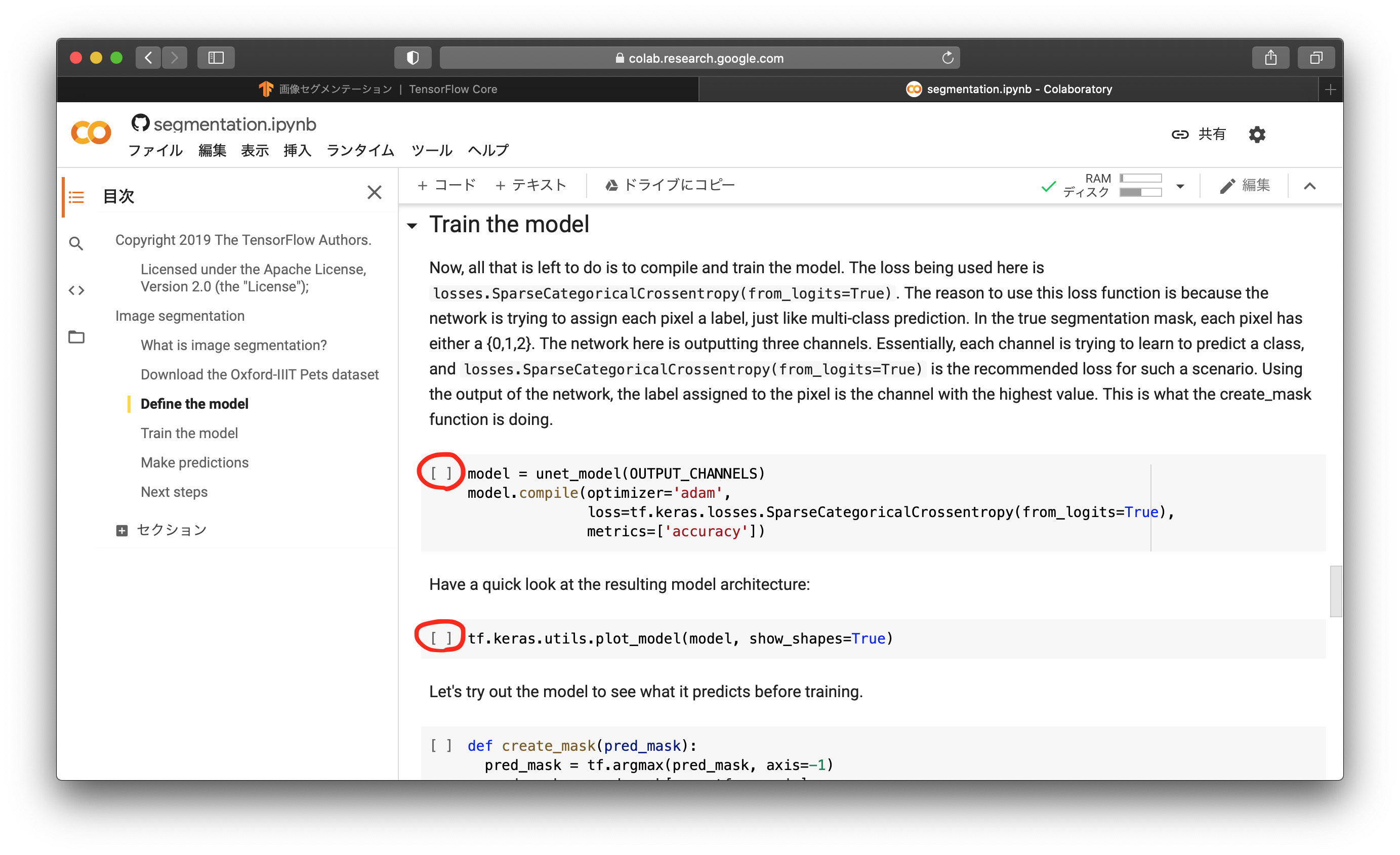
ネットワークモデルができたので、その学習準備を行います。学習時のオプティマイザーをadamに、損失関数をクロスエントロピー誤差に設定します。そして、モデルの全体像を表示します。
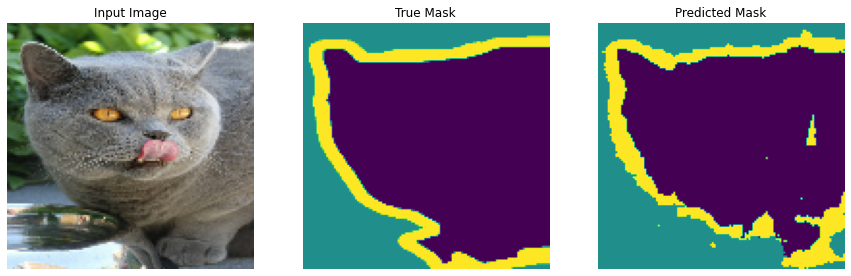
学習前に、とりあえず今のままの状態で推論を行ったら、どのようなマスクが出力されるのかを見ておきます。赤丸を上から順にクリックすると、以下のような画像が出てくると思います。一番右の推論マスクを見ると、まだ、まともなマスク画像が出力されていないのがよく分かります。

学習中の進行状況の表示方法を規定し、20エポックの学習を行います。赤丸を上から順にクリックしましょう。学習には時間がかかります。
最後に、学習過程の損失と正答率のグラフを出し、推論結果を表示します。赤丸を上から順に実行しましょう。
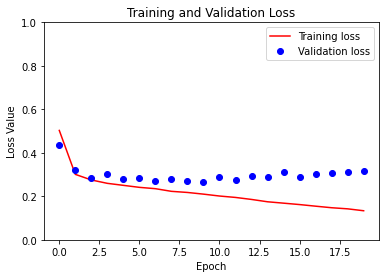
学習時のLossは下がっていますが、テストのLossはあまり下がらず、逆に少し上がってきているようにも見えます。もしかしたら少し過学習気味になっているのかもしれません。その場合、フリップだけではなく、ズーム・シフト・回転のデータ拡張を入れることで、この過学習を抑えることができると思われます。


まとめ
セグメンテーションのチュートリアルについて解説しました。基本的に、上から順にクリックしていくだけなので、実行は楽ですね。あとは、中身の概要を理解することが重要だと思います。他にも、いくつかチュートリアルがあるので、順次解説していきたいと思います。
