
活性化関数
各層の計算は、重みの掛け算とバイアスの足し算の後、活性化関数を通します。活性化関数は、非線形関数であることが必須です。というのは、もし線形関数を用いてしまうと、せっかく層を重ねても、全て線形結合になってしまうので、線形の式に帰結してしまいます。つまり複数の層を持っていても、それは1層の場合と同じになってしまうとうわけです。ということで、非線形の活性化関数を使うことは、ディープラーニングでは必須と言えるのです。
活性化関数の進化
ディープラーニング前のニューラルネットワークでは活性化関数としてステップ関数を用いていました。これが、深いネットワークの学習が適切にできなかった原因でもありました。その後、シグモイド(sigmoid)やハイパボリックタンジェント(tanh)が使われるようになり、さらにランプ関数(ReLU : Rectified Linear Units)が登場して、ディープラーニングが飛躍的に進化しました。
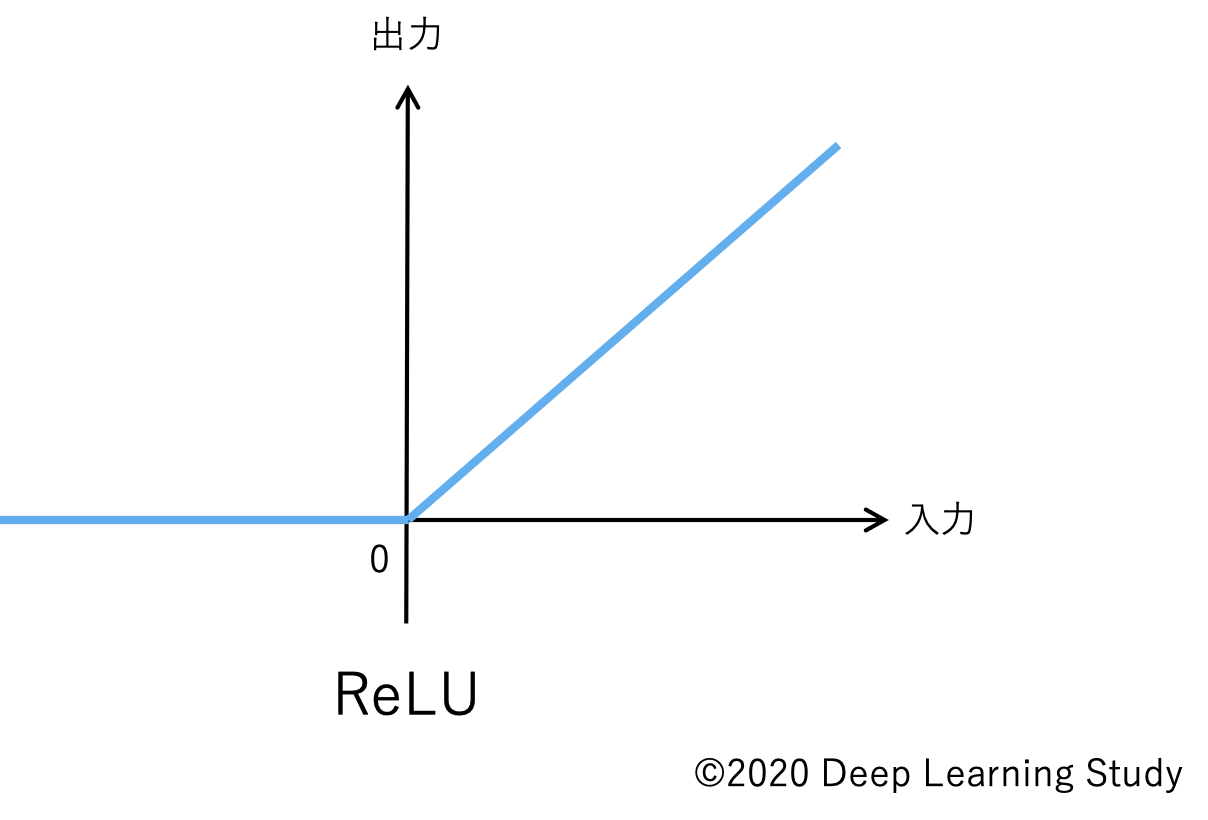
図のようなReLUを適用すると、勾配消失問題が起こりにくくなり、深いネットワークでも学習がスムーズに進みます。現在ではさらに、LeakyReLUやSwishなど、より効率の良い活性化関数が提案されており、まだまだ進化中です。
まとめ
活性化関数の進化は、ディープラーニング技術進化にはなくてはならないものでした。特に、ディープラーニングはネットワークが深くなればなるほど能力を発揮してくるので、勾配消失問題が起こりにくい活性化関数が求められます。ReLUは、現在でもよく使われ、深いネットワークに適しています。